Driver 和Executor是和计算相关的组件,Master和Worker是和资源调度相关的组件,如果让资源和计算之间直接交互,耦合性太强,所以就添加ApplicationMaster组件,如果Driver需要申请资源,那么就找ApplicationMaster申请资源,而ApplicationMaster在向Master申请资源,这样可以解耦。
当Spark Application运行在集群上时,主要有四个部分组成,如下示意图:
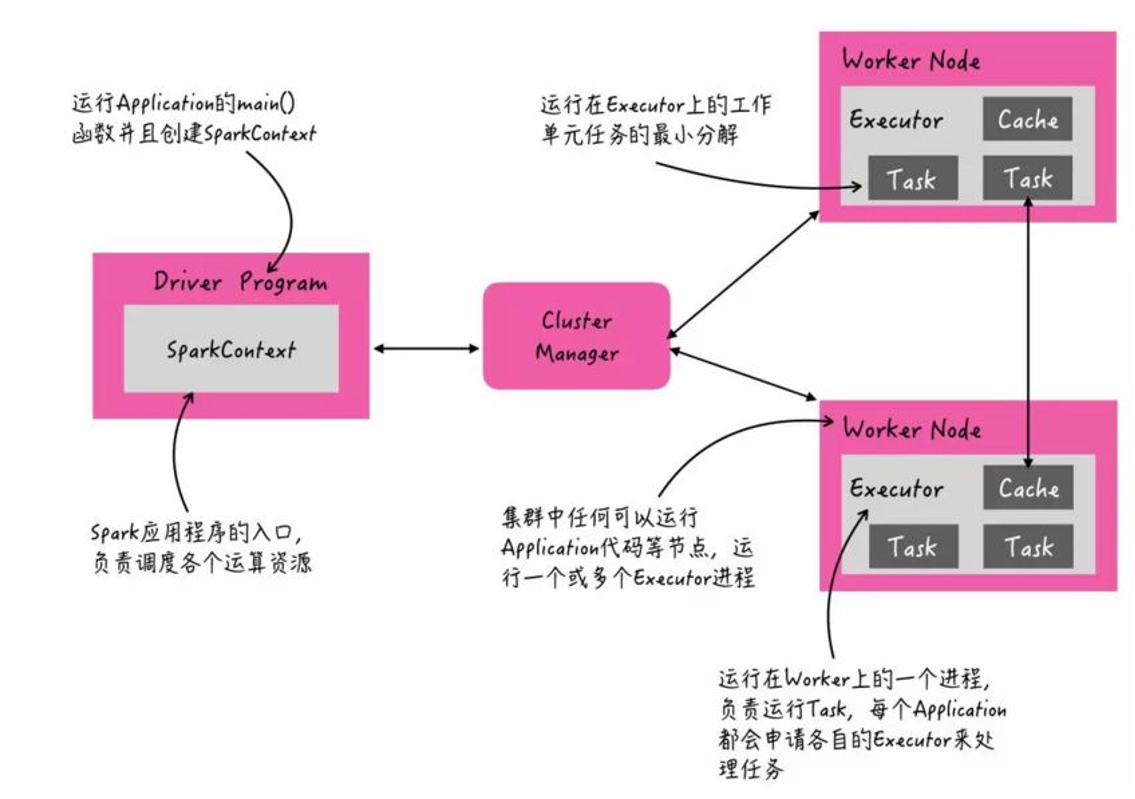
- Driver:是一个JVM Process 进程,编写的Spark应用程序就运行在Driver上,由Driver进程执行;
- Master(ResourceManager):是一个JVM Process 进程,主要负责资源的调度和分配,并进行集群的监控等职责;有多种类型的集群管理器。
- Worker(NodeManager):是一个JVM Process 进程,一个Worker运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储RDD的某个或某些partition;另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算。
- Executor:是一个JVM Process 进程,一个Worker(NodeManager)上可以运行多个Executor,Executor通过启动多个线程(task)来执行对RDD的partition进行并行计算,也就是执行我们对RDD定义的例如map、flatMap、reduce等算子操作。
Driver、Executor:计算资源
Master、Worker:资源调度
一个Worker上面可能有多个Executor进程
一个Executor进程可能有多个task线程
Spark支持多种集群管理器(Cluster Manager),取决于传递给SparkContext的MASTER环境变量的值:local、spark、yarn,区别如下:

在Standalone模式下运行,根据Driver程序运行在哪里分为两种模式,默认是client模式:
- Client部署模式:7077,
- Cluster部署模式:6066
在Yarn集群模式下运行,也有两种部署模式:
- yarn-client:Driver运行在本地,Executor运行在Yarn集群上
- yarn-cluster:Driver运行在Yarn集群上面,Executor运行在yarn集群上面
client mode
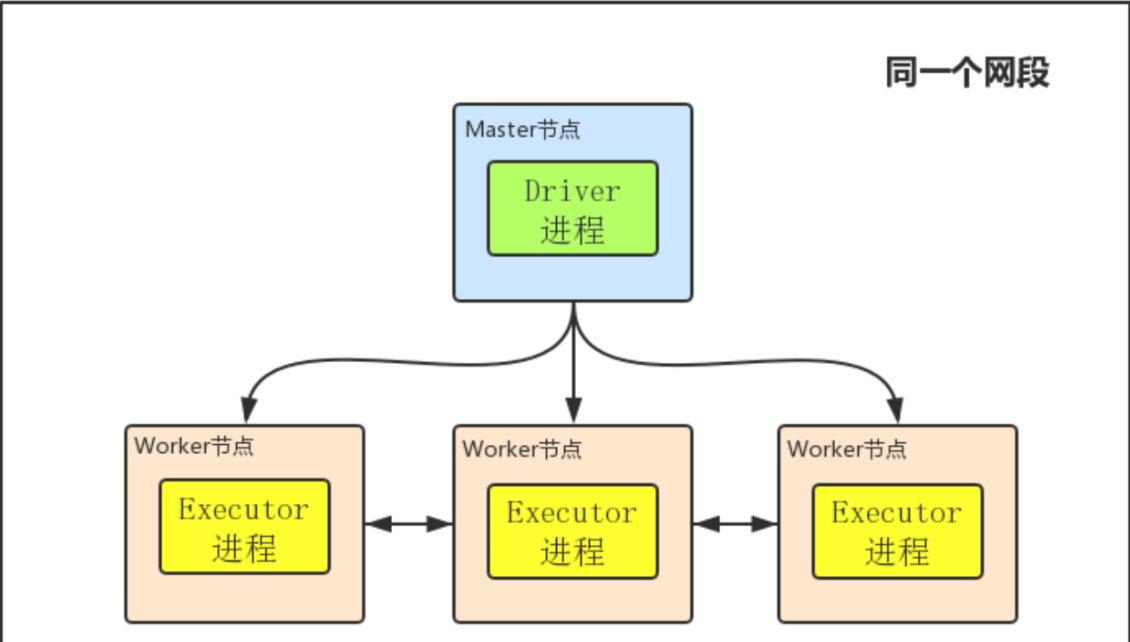
首先明白几个基本概念:Master节点就是你用来提交任务,即执行bin/spark-submit命令所在的那个节点;Driver进程就是开始执行你Spark程序的那个Main函数,虽然我这里边画的Driver进程在Master节点上,但注意Driver进程不一定在Master节点上,它可以在任何节点;Worker就是Slave节点,Executor进程必然在Worker节点上,用来进行实际的计算。
- client mode下Driver进程运行在Master节点上,不在Worker节点上,所以相对于参与实际计算的Worker集群而言,Driver就相当于是一个第三方的“client”。
- 正由于Driver进程不在Worker节点上,所以其是独立的,不会消耗Worker集群的资源
- client mode下Master和Worker节点必须处于同一片局域网内,因为Drive要和Executorr通信,例如Drive需要将Jar包通过Netty HTTP分发到Executor,Driver要给Executor分配任务等。
- client mode下没有监督重启机制,Driver进程如果挂了,需要额外的程序重启
cluster mode
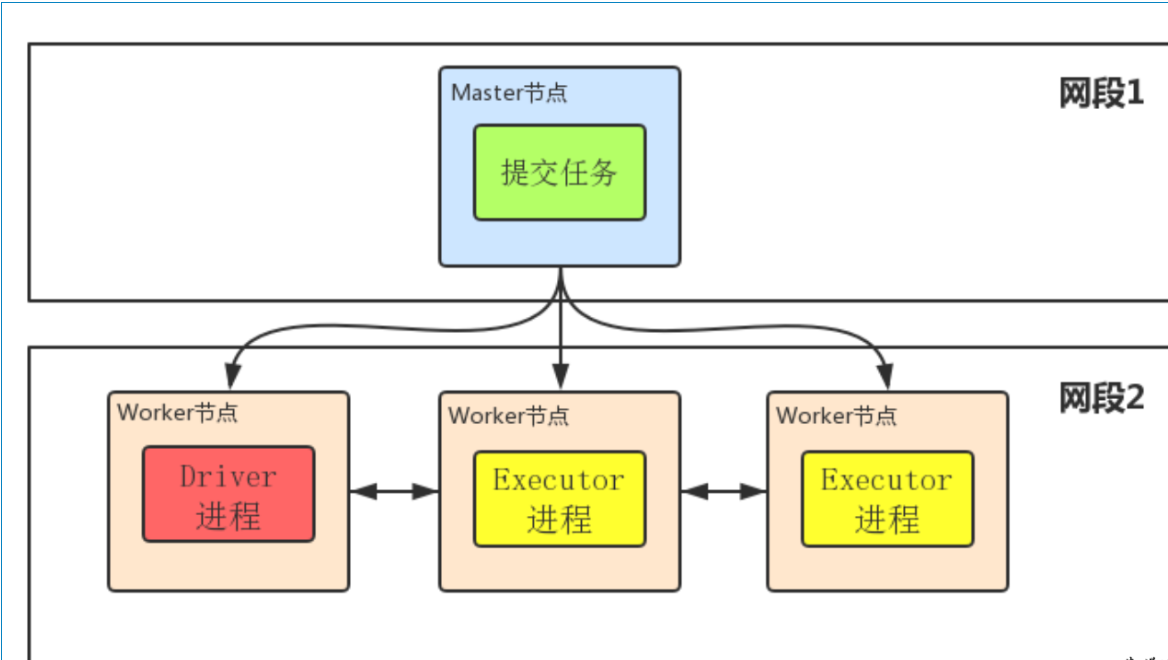
- Driver程序在worker集群中某个节点,而非Master节点,但是这个节点由Master指定
- Driver程序占据Worker的资源
- cluster mode下Master可以使用–supervise对Driver进行监控,如果Driver挂了可以自动重启
- cluster mode下Master节点和Worker节点一般不在同一局域网,因此就无法将Jar包分发到各个Worker,所以cluster mode要求必须提前把Jar包放到各个Worker几点对应的目录下面
是选择client mode还是cluster mode呢?
- 一般来说,如果提交任务的节点(即Master)和Worker集群在同一个网络内,此时client mode比较合适
- 如果提交任务的节点和Worker集群相隔比较远,就会采用cluster mode来最小化Driver和Executor之间的网络延迟
yarn client模式:driver在当前提交任务的节点上,也就是运行在本地,可以打印任务运行的日志信息。
yarn cluster模式:driver在AppMaster所有节点上,分布式分配,不能再提交任务的本机打印日志信息
关于sparkON-yarn详细请看:spark-on-yarn
引入
之前我们使用提交任务都是使用spark-shell提交,spark-shell是Spark自带的交互式Shell程序,方便用户进行交互式编程,用户可以在该命令行下可以用scala编写spark程序,适合学习测试时使用!
示例
- spark-shell可以携带参数
- spark-shell --master local[N] 数字N表示在本地模拟N个线程来运行当前任务
- spark-shell --master local[*] *表示使用当前机器上所有可用的资源
- 默认不携带参数就是--master local[*]
- spark-shell --master spark://node01:7077,node02:7077 表示运行在集群上
引入
spark-shell交互式编程确实很方便我们进行学习测试,但是在实际中我们一般是使用IDEA开发Spark应用程序打成jar包交给Spark集群/YARN去执行,所以我们还得学习一个spark-submit命令用来帮我们提交jar包给spark集群/YARN,spark-submit命令是我们开发时常用的!
提交任务到Local集群
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master local[2] \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.11-3.0.1.jar \
10或提交任务到Standalone集群
--master spark://node1:7077 \或提交任务到Standalone-HA集群
--master spark://node1:7077,node2:7077 \或使用SparkOnYarn的Client模式提交到Yarn集群
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 1 \
--total-executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.12-3.0.1.jar \
10或使用SparkOnYarn的Cluster模式提交到Yarn集群
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 1 \
--total-executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.12-3.0.1.jar \
10使用【spark-submit】提交应用语法如下:
spark-submit [options] <app jar | python file> [app arguments]如果使用Java或Scala语言编程程序,需要将应用编译后达成Jar包形式,提交运行。
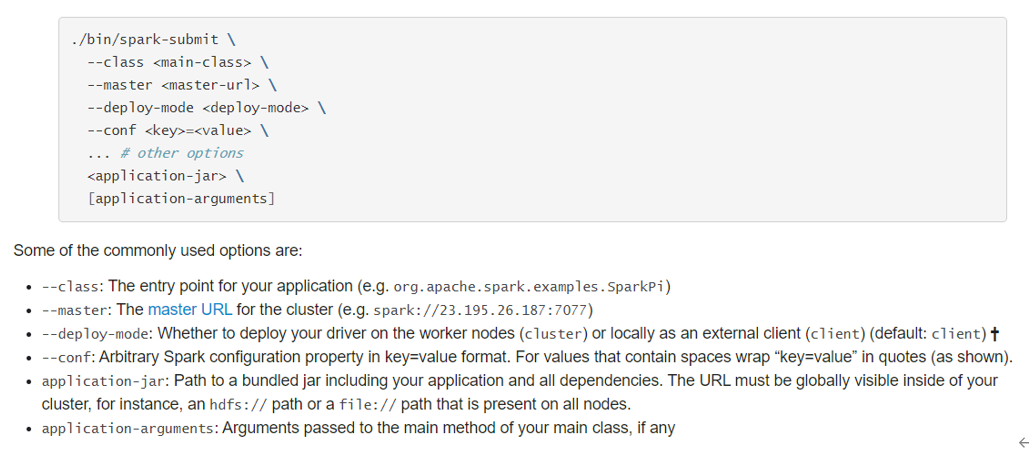
提交运行Spark Application时,有些基本参数需要传递值,如下所示:

动态加载Spark Applicaiton运行时的参数,通过--conf进行指定,如下使用方式:

每个Spark Application运行时都有一个Driver Program,属于一个JVM Process进程,可以设置内存Memory和CPU Core核数。

每个Spark Application运行时,需要启动Executor运行任务Task,需要指定Executor个数及每个Executor资源信息(内存Memory和CPU Core核数)。

# Run application locally on 8 cores
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[8] \
/path/to/examples.jar \
100
# Run on a Spark standalone cluster in client deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# Run on a Spark standalone cluster in cluster deploy mode with supervise
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# Run on a YARN clusterexport HADOOP_CONF_DIR=XXX
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \ # can be client for client mode
--executor-memory 20G \
--num-executors 50 \
/path/to/examples.jar \
1000
# Run a Python application on a Spark standalone cluster
./bin/spark-submit \
--master spark://207.184.161.138:7077 \
examples/src/main/python/pi.py \
1000
# Run on a Mesos cluster in cluster deploy mode with supervise
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master mesos://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
http://path/to/examples.jar \
1000
# Run on a Kubernetes cluster in cluster deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master k8s://xx.yy.zz.ww:443 \
--deploy-mode cluster \
--executor-memory 20G \
--num-executors 50 \
http://path/to/examples.jar \
1000Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。如下图所示,它展示了一个 Spark 执行时的基本结构。图形中的Driver 表示 master,负责管理整个集群中的作业任务调度。图形中的Executor 则是 slave,负责实际执行任务。
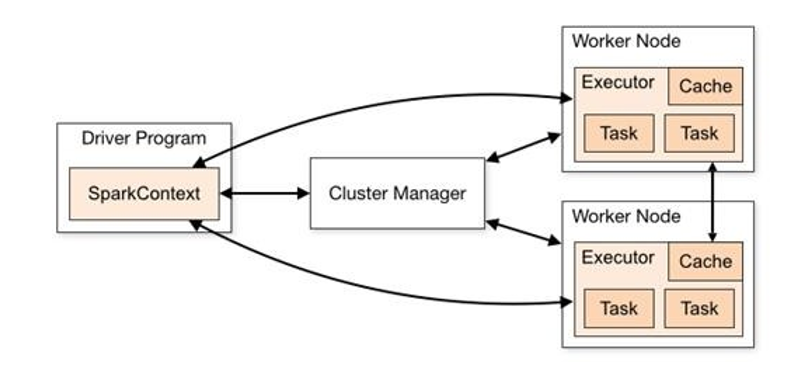
driver:执行器,执行我们的main方法,创建SparkContext环境。
Executor:执行器,具体负责计算的节点。
由上图可以看出,对于 Spark 框架有两个核心组件:
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。Spark驱动器是控制你应用程序的进程,他负责控制整个spark应用程序的执行并且维护着spark集群的状态,也就是维护执行器的任务和状态,他必须和集群管理器进行交互才可以获得物理资源并启动执行器,总的来说,spark驱动器只是物理机上的一个进程,负责维护集群运行的应用程序的状态。
Driver 在Spark 作业执行时主要负责:
- 将用户程序转化为作业(job)
- 在 Executor 之间调度任务(task)
- 跟踪Executor 的执行情况
- 过UI 展示查询运行情况
实际上,我们无法准确地描述Driver 的定义,因为在整个的编程过程中没有看到任何有关Driver 的字眼。所以简单理解,所谓的 Driver 就是驱使整个应用运行起来的程序,也称之为Driver 类。
Spark Executor 是集群中工作节点(Worker)中的一个 JVM 进程(一个Worker种可以有多个Executor进程),负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有Executor 节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点上继续运行。
spark执行器也是一个进程,他负责执行由spark驱动器分配的任务,执行器的核心功能是:完成驱动器分配的任务,运行他们,并报告结果的状态和执行的结果,每一个spark应用程序都有自己的执行器进程。
Executor 有两个核心功能:
- 负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程,也就是返回给driver
- 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
Spark 集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调度的功能,所以环境中还有其他两个核心组件:Master 和 Worker,这里的 Master 是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责,类似于 Yarn 环境中的 RM(resourcemanager), 而Worker 呢,也是进程,一个 Worker 运行在集群中的一台服务器上,由 Master 分配资源对数据进行并行的处理和计算,类似于 Yarn 环境中 NM(namenode)。
Hadoop 用户向 YARN 集群提交应用程序时,提交程序中应该包含ApplicationMaster,ApplicationMaster其实就可以看作是一个作业的代理,在整个作业执行过程种,负责作业监控和资源的申请,用于向资源调度器申请执行任务的资源容器 Container,运行用户自己的程序任务 job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。
说的简单点就是,ResourceManager(资源)和Driver(计算)之间的解耦合靠的就是ApplicationMaster。
spark驱动器和执行器并不是孤立存在的,集群管理器会将他们联系起来,集群管理器负责维护一组运行spark应用程序的机器,集群管理器也拥有自己的“driver驱动器“,(也就是master和worker)的抽象,核心区别是集群管理器管理的是物理机器,而不是进程,spark目前支持三种集群管理器,一个是简单的内置的独立的计算管理器,Apache Mesos和hadoop yarn集群管理器。
Spark Executor 是集群中运行在工作节点(Worker)中的一个 JVM 进程,是整个集群中的专门用于计算的节点。在提交应用中,可以提供参数指定计算节点的个数,以及对应的资源。这里的资源一般指的是工作节点 Executor 的内存大小和使用的虚拟 CPU 核(Core)数量。
应用程序相关启动参数如下:
| 名称 | 说明 |
|---|---|
| --num-executors | 配置 Executor 的数量 |
| --executor-memory | 配置每个 Executor 的内存大小 |
| --executor-cores | 配置每个 Executor 的虚拟 CPU core 数量 |
在分布式计算框架中一般都是多个任务同时执行,由于任务分布在不同的计算节点进行计算,所以能够真正地实现多任务并行执行,记住,这里是并行,而不是并发。这里我们将整个集群并行执行任务的数量称之为并行度。那么一个作业到底并行度是多少呢?这个取决于框架的默认配置。应用程序也可以在运行过程中动态修改。
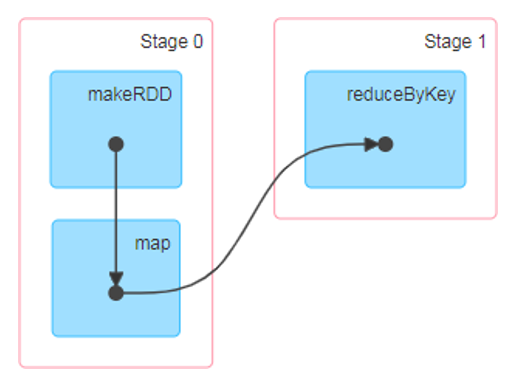
- 大数据计算引擎框架我们根据使用方式的不同一般会分为四类:
- 其中第一类就是Hadoop 所承载的 MapReduce,它将计算分为两个阶段,分别为 Map 阶段和 Reduce 阶段。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。
- 由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如Tez 以及更上层的Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的Tez 和Oozie 来说,大多还是批处理的任务。
- 接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及实时计算。
- 这里所谓的有向无环图,并不是真正意义的图形,而是由Spark 程序直接映射成的数据流的高级抽象模型。简单理解就是将整个程序计算的执行过程用图形表示出来,这样更直观, 更便于理解,可以用于表示程序的拓扑结构。
- DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。
- 在spark中的作用就是规划多个作业的执行顺序,防止出现环发生死锁。
所谓的提交流程,其实就是我们开发人员根据需求写的应用程序通过Spark 客户端提交给 Spark 运行环境执行计算的流程。在不同的部署环境中,这个提交过程基本相同,但是又有细微的区别,我们这里不进行详细的比较,但是因为国内工作中,将 Spark 引用部署到Yarn 环境中会更多一些,所以本课程中的提交流程是基于 Yarn 环境的。
提交过程
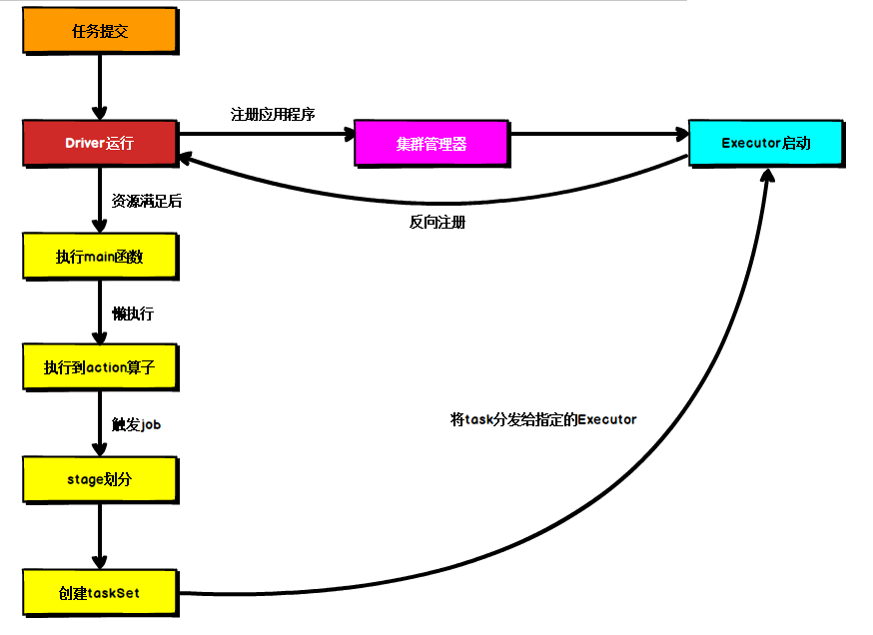
可以看到提交过程分成两条线,集群管理器那条线是负责申请资源,因为运行作业需要资源,执行main这一条线就是我们编写的逻辑程序,最后把我们的程序提交到executor节点上面进行执行
Spark 应用程序提交到 Yarn 环境中执行的时候,一般会有两种部署执行的方式:Client(运行在集群之外) 和 Cluster(运行在集群里面)。两种模式主要区别在于:Driver程序的运行节点位置。
Client 模式将用于监控和调度的Driver 模块在客户端执行,而不是在 Yarn 中,所以一般用于测试。
- Driver 在任务提交的本地机器上运行
- Driver 启动后会和ResourceManager 通讯申请启动ApplicationMaster
- ResourceManager 分配 container,在合适的NodeManager 上启动ApplicationMaster,负责向ResourceManager 申请 Executor 内存
- ResourceManager 接到 ApplicationMaster 的资源申请后会分配 container,然后ApplicationMaster 在资源分配指定的NodeManager 上启动 Executor 进程
- Executor 进程启动后会向Driver 反向注册,Executor 全部注册完成后Driver 开始执行main 函数
- 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个stage 生成对应的TaskSet,之后将 task 分发到各个Executor 上执行。
Cluster 模式将用于监控和调度的 Driver 模块启动在Yarn 集群资源中执行。一般应用于实际生产环境。
- 在 YARN Cluster 模式下,任务提交后会和ResourceManager 通讯申请启动ApplicationMaster,
- 随后ResourceManager 分配 container,在合适的 NodeManager 上启动 ApplicationMaster,此时的 ApplicationMaster 就是Driver,Driver和ApplicationMaster 运行在一个节点上面。
- Driver 启动后向 ResourceManager 申请Executor 内存,ResourceManager 接到ApplicationMaster 的资源申请后会分配container,然后在合适的NodeManager 上启动Executor 进程
- Executor 进程启动后会向Driver 反向注册,Executor 全部注册完成后Driver 开始执行main 函数,
- 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个stage 生成对应的TaskSet,之后将 task 分发到各个Executor 上执行。
spark运行流程图
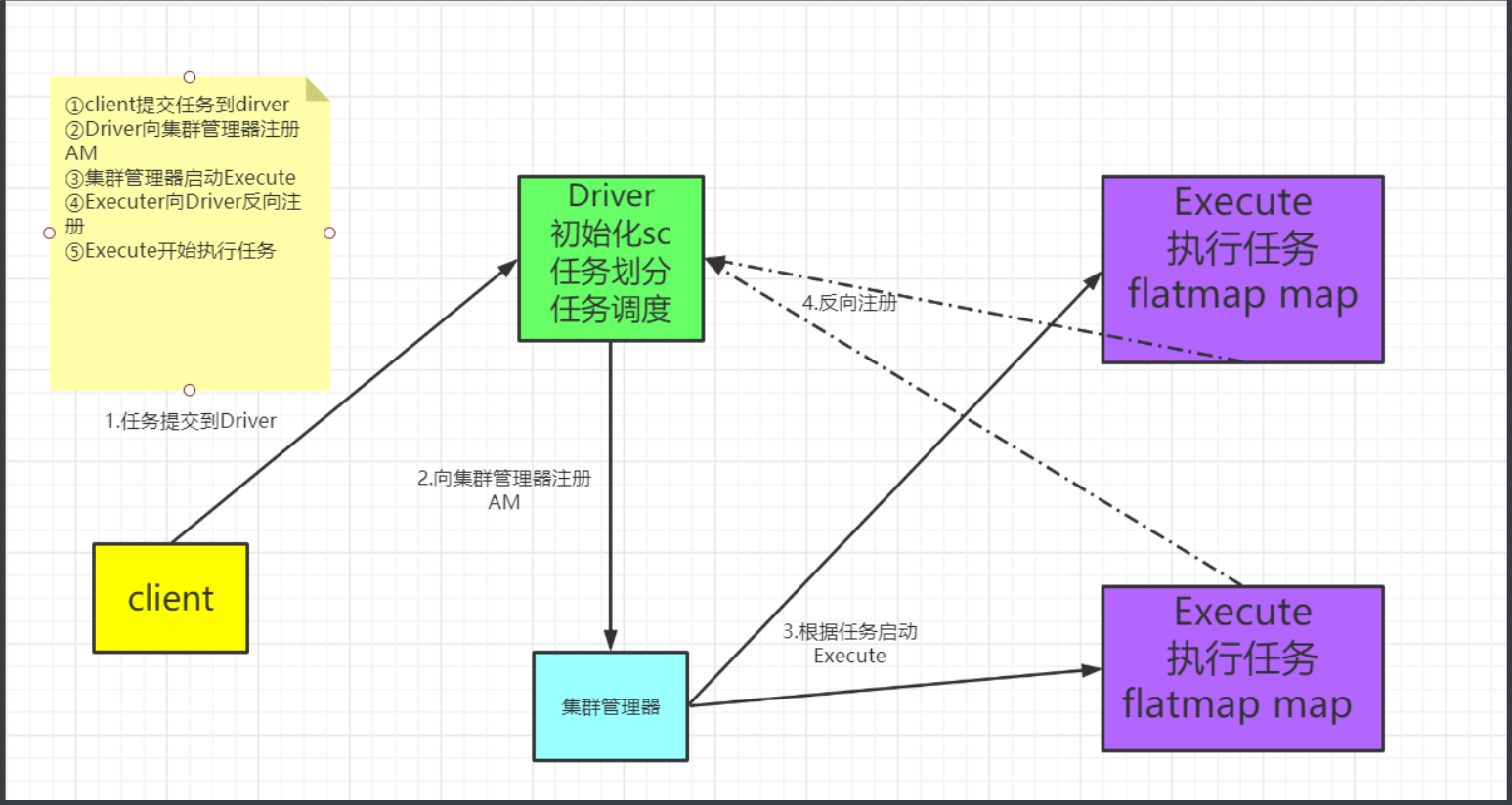
通用执行流程
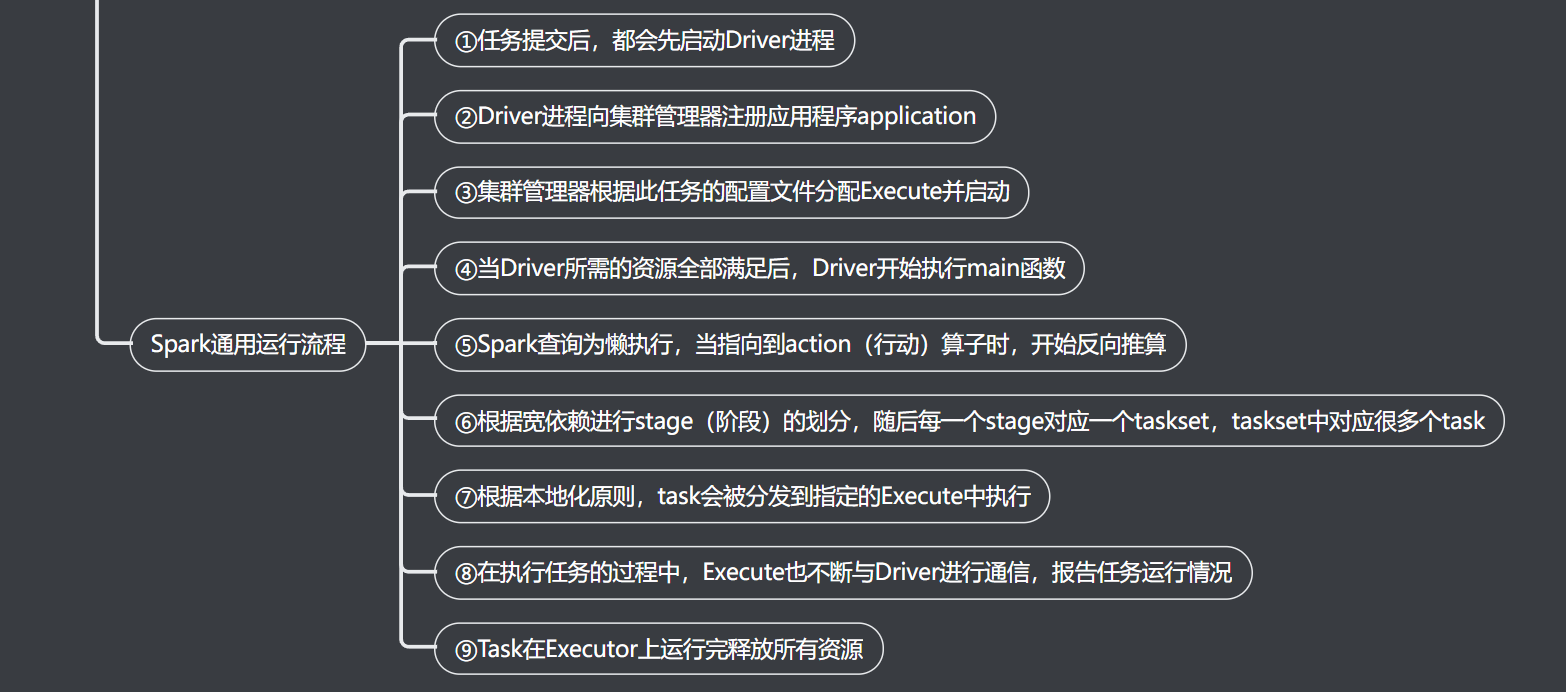
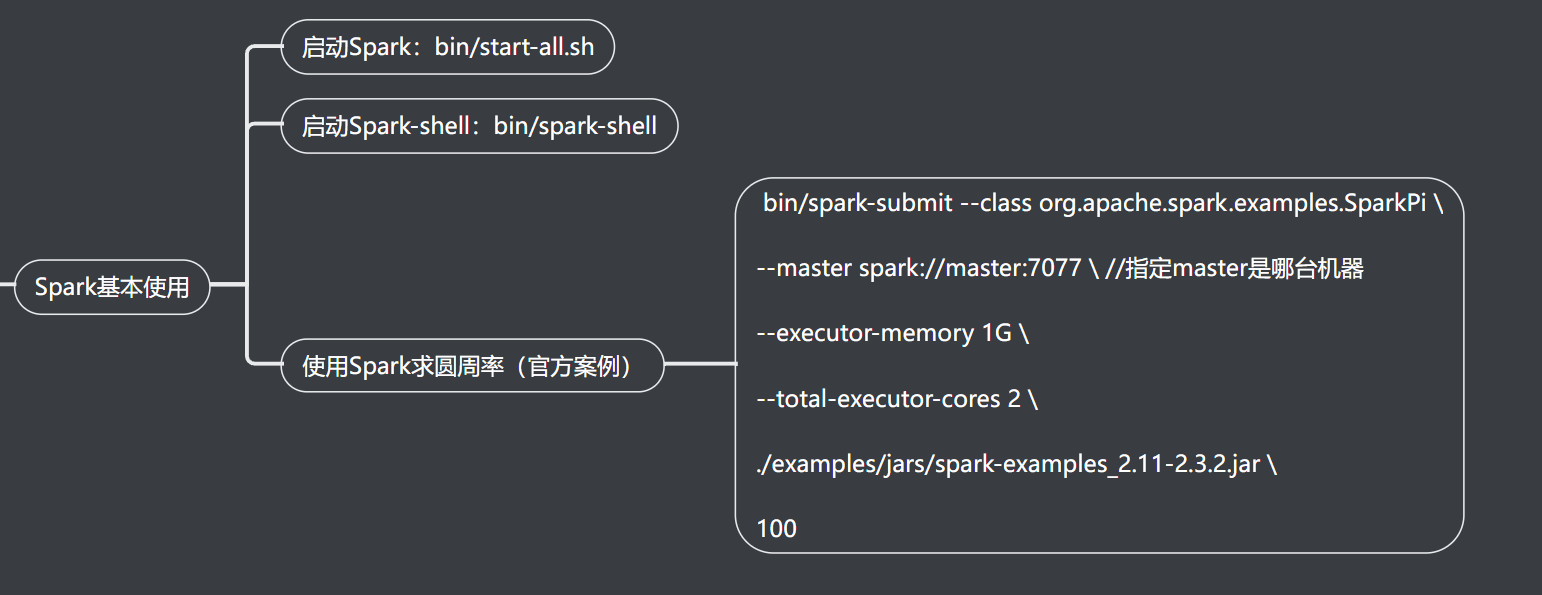
Spark基本使用