- Open a terminal
- Preferably, activate a virtual environment
- Install the dependencies
cd podcasts-api/
pip3 install -r requirements.txtIn case you have trouble using requirements.txt, you can always install the
modules individually:
pip3 install requests
pip3 install pandas
pip3 install SQLAlchemy
pip3 install flask
pip3 install flask_sqlalchemy
pip3 install flask_marshmallow
pip3 install marshmallow-sqlalchemy
pip3 install jwtType in the terminal
python3 app.pyThe first task that the code performs is the database creation. If it is the first time running the project, a message that says 'populating db...' will appear. When it its finished, it will display the message: 'db was populated succesfully!'
You have to authenticate, in order to generate a token to use for calling the APIs.
- Open up postman or another REST client and use the endpoint:
http://localhost:5000/user - Define a name and a password like in the example
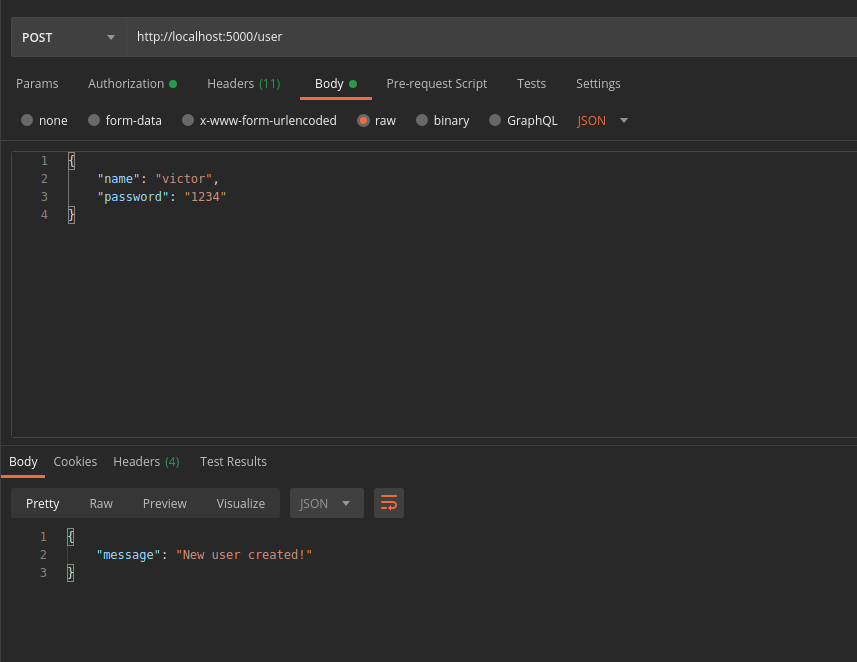
- If successful, a message with
new user created!will get displayed.
- Use the endpoint
http://localhost:5000/login - In Postman's
Authorizationtab, provide your username and password - A token will get generated!
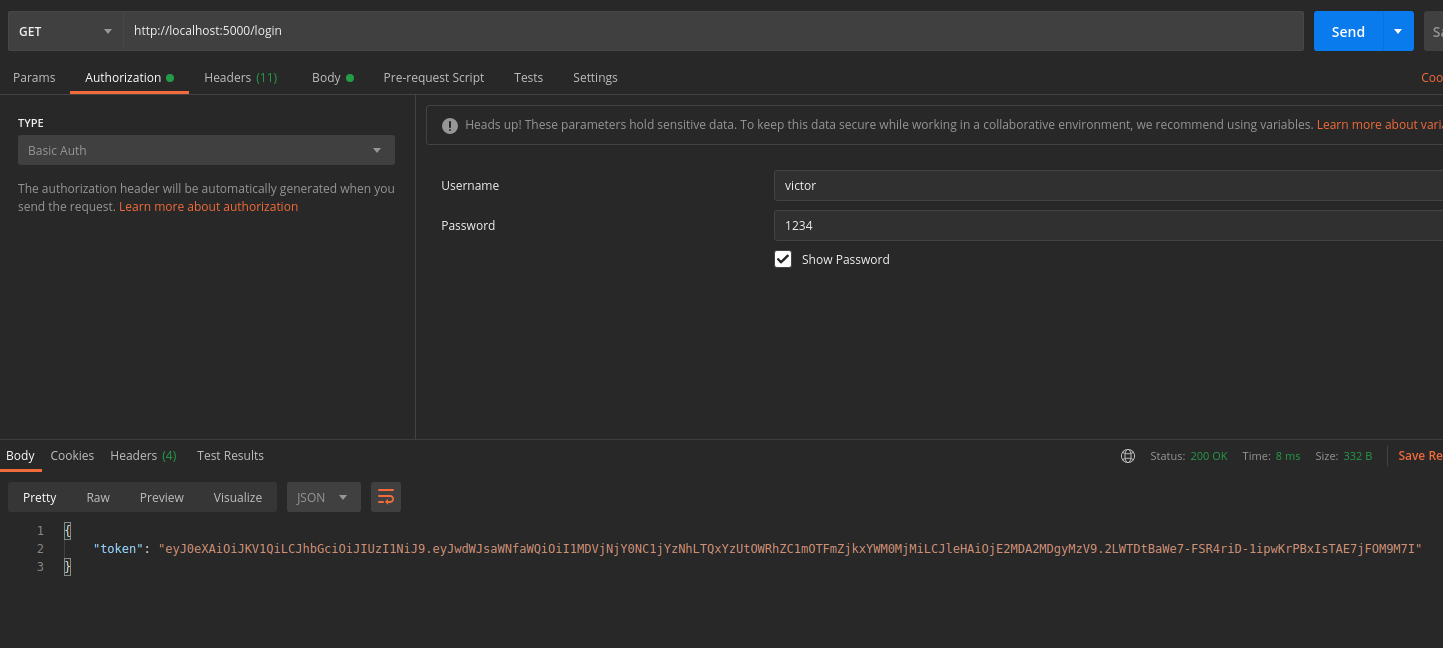
IMPORTANT: COPY THE PROVIDED TOKEN!
- Create a
x-access-tokenheader, and paste the token you copied from last step.
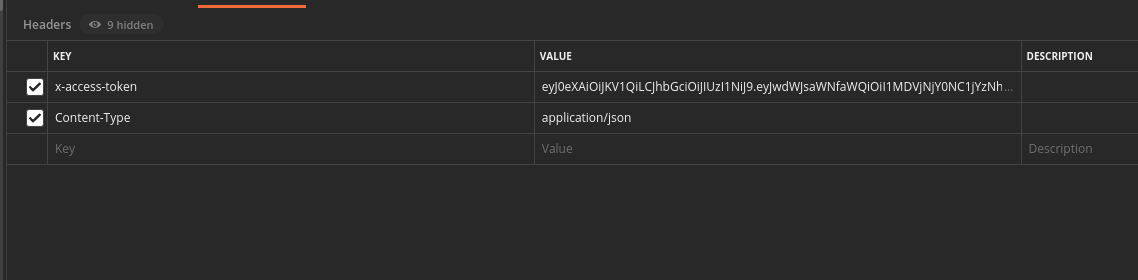
Now you are ready to call the APIs!
Schema used for the exercise
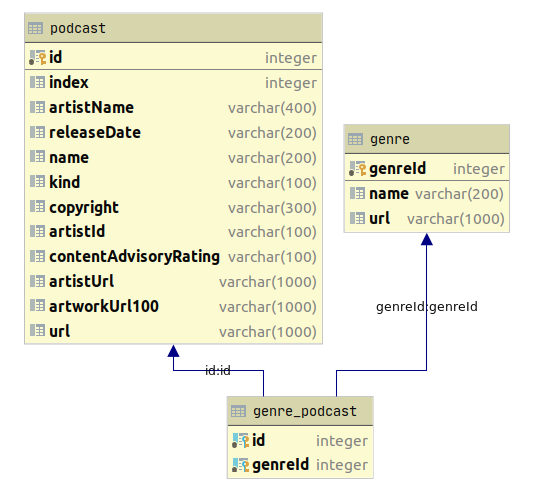
I decided to split the data in three different tables: genre, podcast and genre_podcast, which is the middle table between the many to many relationship of genre and podcast. I have used pandas for this stage, given the simplicity for dropping duplicates and storing the dataframe directly to a table.
- Retrieves the json from a remote URL
- Separates the multivaluated column genres
- Creates pandas dataframes of genre, podcast and genre_podcast
- Create empty tables and their relationships.
- Inserts dataframes into the tables.
Note: Given the fact SQL tables don't store the rows in insertion order, the pd index was used as a helper
column to preserver the order. This index field is not visible when querying the data.
Service to provide a search lookup within the podcasts
The function search_lookup implements the search and filters the podcasts table using a LIKE operator
to search for a given name.
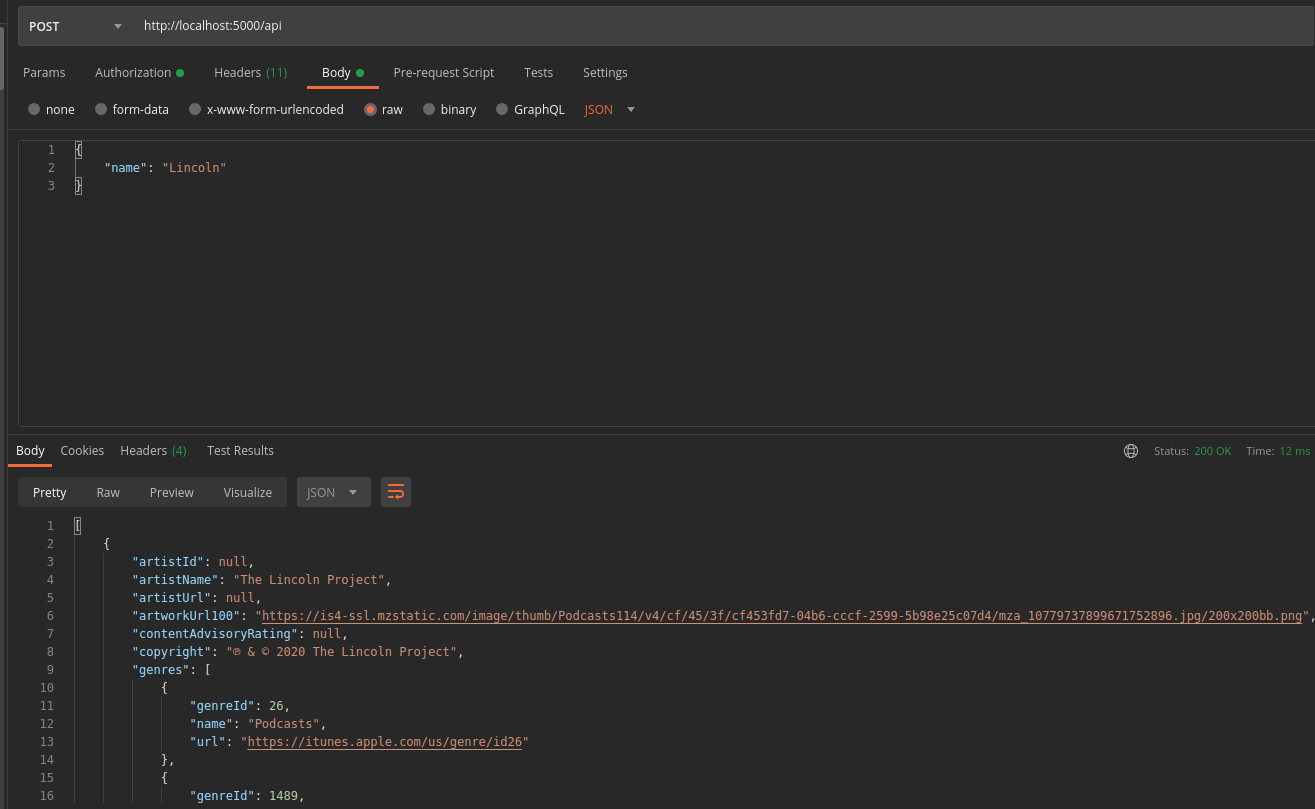
- use the endpoint
http://localhost:5000/api - use a
POSTrequest - Send a json containing a
namekey and its value in string format
Service that would allow to save the top 20 podcasts to a separate JSON File
The store_top_20 function uses the order_by function provided by flask-sqlalchemy to sort the podcasts using the
index column.
- use the endpoint
http://localhost:5000/api/top20 - use a
GETrequest
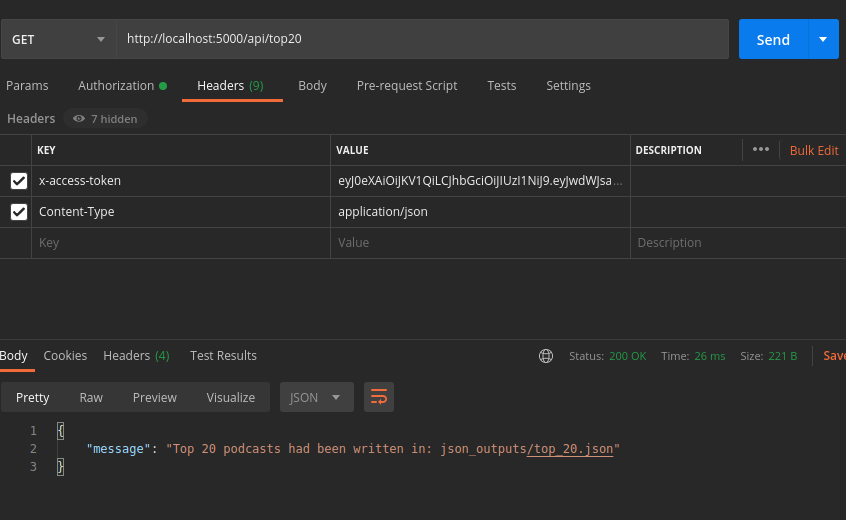
Output got saved to
json_oututsfolder in project!
- use the endpoint
http://localhost:5000/api/swap - use a
GETrequest
A service to replace the top 20 podcasts for the bottom 20 to said JSON File
Using array slicing, its easy to swap the order of the rows in swap_top_bottom() function.
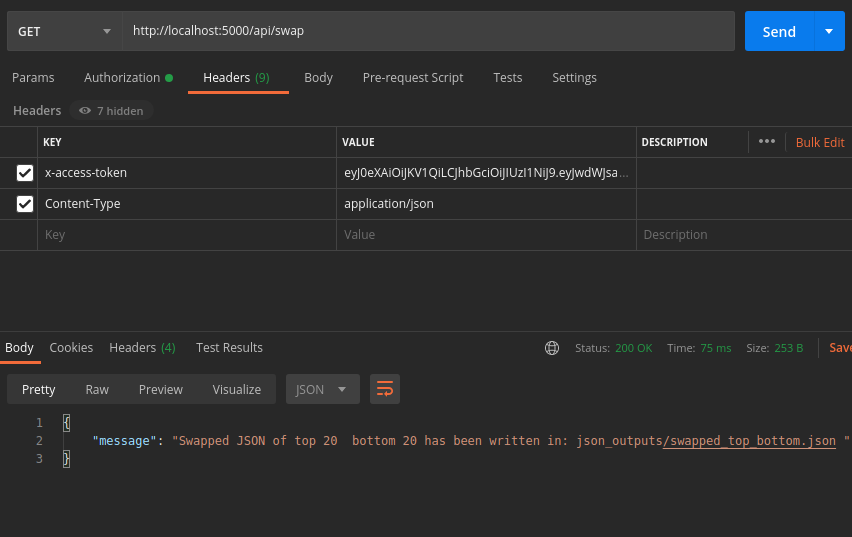
Output got saved to
json_oututsfolder in project!
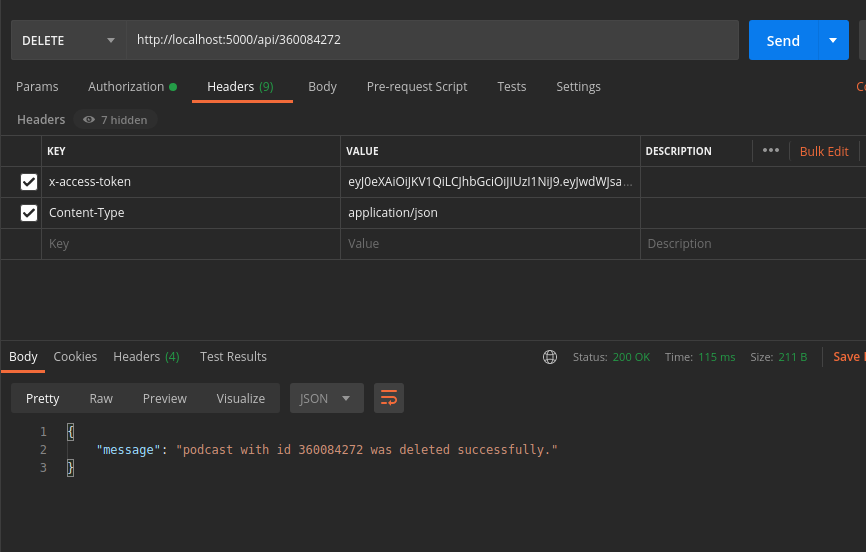
A service to remove a podcast, using a given identifier
- use the endpoint
http://localhost:5000/api/360084272(You can use any id of the podcast json) - use a
DELETErequest.
The function delete_podcast(id) identifier used for deleting is 'id' (podcast id), given the fact it's been used as primary key of the podcasts
table.
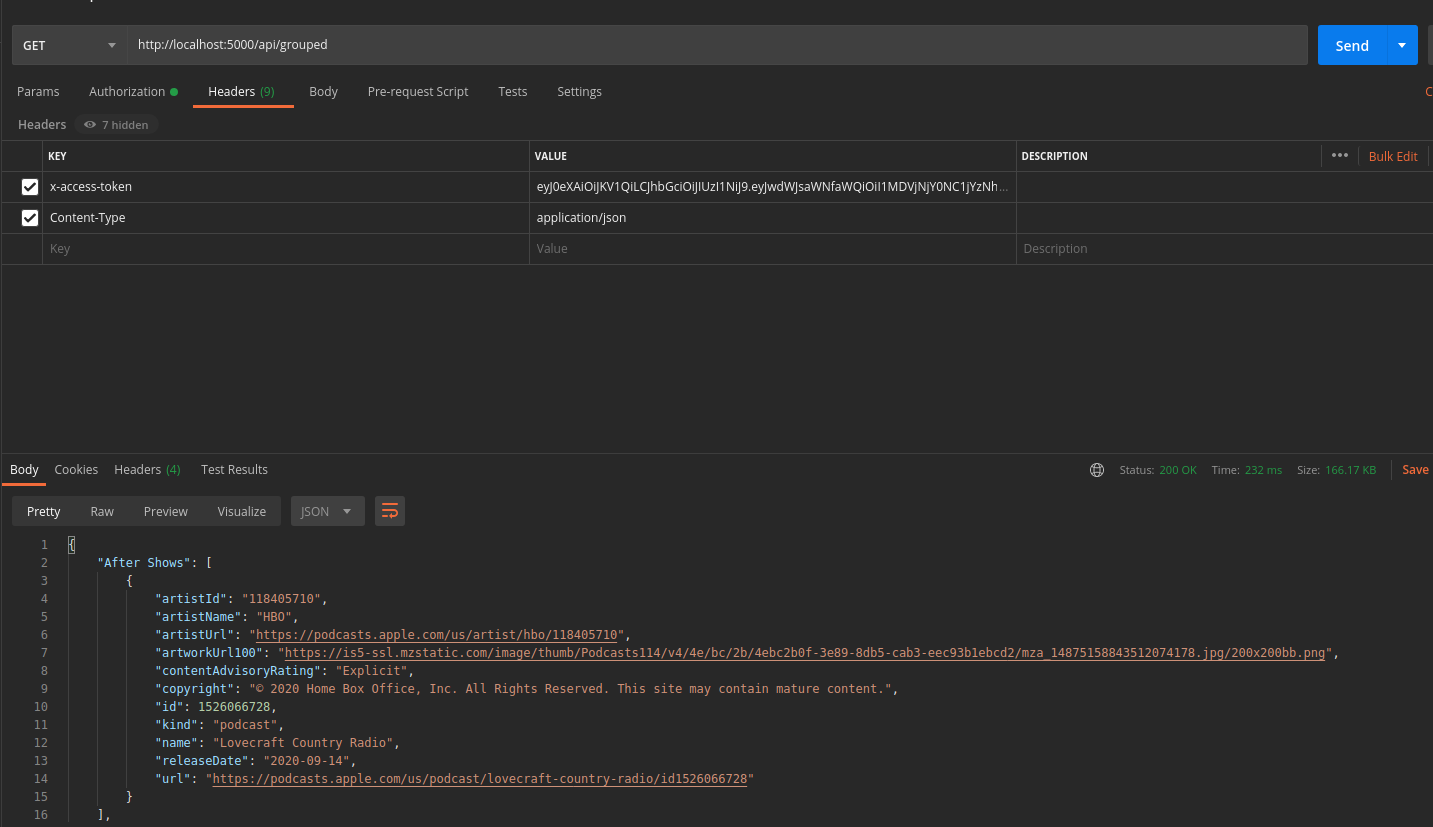
Create a service to return the podcasts grouped by genres, even if they appear as duplicates within some of the categories.
- use the endpoint
http://localhost:5000/api/grouped - use a
GETrequest
The podcasts_by_genres() performs a query to fetch the names of the genres and the id of the podcasts. Next,
a for lop iterates over each row to perform a search of the podcast object and append it to a genres dictionary that wil return
the desired output.