

sociaML is a Python package designed for the automatic analysis of videos. It facilitates the extraction of audiovisual and textual features from videos, offering a comprehensive toolkit for researchers and developers working with multimedia data. With sociaML you can extract features relevant downstream research (eg social sciences) with little knowledge machine learning or even Python.
Warning
Emotion extraction from videos is currently not working due to a dependency conflict! Will hopefully be fixed soon.
- Transcription and Diarization: Utilizes Whisper for transcription and diarization.
- Anonymization: Incorporates Presidio for automatic anonymization of data.
- Audio Features Extraction: Extracts various audio features like emotions, MFCCs, speaking times, and silent times.
- Visual Features Extraction: Analyzes facial emotions, Facial Action Coding System, and facial posture.
- Textual Features Extraction: Provides analysis on Ekman emotions, sentiment, word/token counts, sentence embeddings, and more.
Make sure you have https://www.ffmpeg.org/ installed on your system. It is a prerequisite for Whisper.
As the API is not stable yet, please install it directly from git
pip install git+https://github.com/davidrzs/sociaMLSociaMLs pipeline can best be summarized by the following graphic:
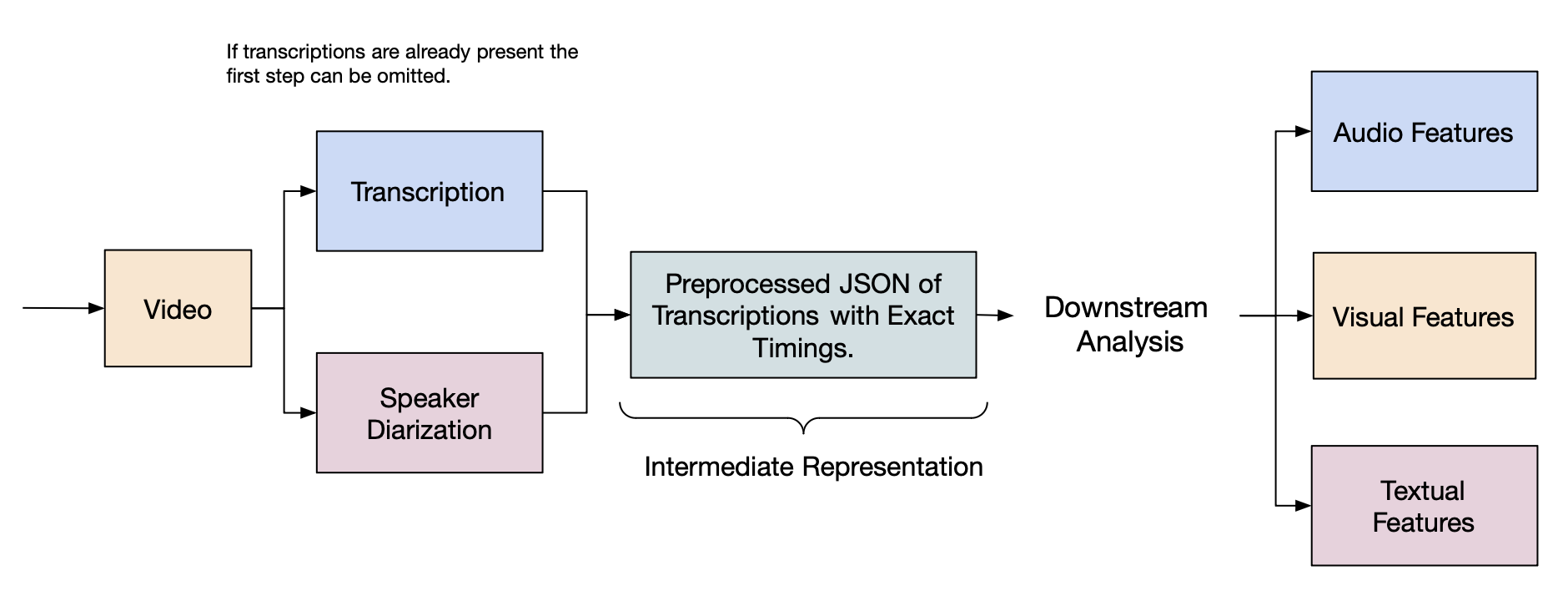
To run the pipeline you might need a Huggingface API Key which you get here.
You can make the huggingface token available as follows:
import os
os.environ["HUGGINGFACE_TOKEN"] = access_tokensociaML offers a preprocessing pipeline that converts videos into an intermediate JSON representation for efficient analysis. This step involves transcription, diarization, and anonymization.
from sociaML.preprocessing import TranscriberAndDiarizer, Anonymizer, AudioExtractor
# Initialize components
transcriber = TranscriberAndDiarizer(pyannote_api_key=os.getenv('HUGGINGFACE_TOKEN'))
anonymizer = Anonymizer()
audio_extractor = AudioExtractor()
# Process video
audio_extractor.process(video_path, audio_path=audio_path)
transcript = transcriber.process(video_path)
transcript = anonymizer.process(transcript)sociaML provides a flexible analysis framework, allowing for the extraction of various features at different levels: Contribution, Participant, and Global.
from sociaML.analysis import Analysis, GlobalAudioEmotionAnalyzer, ParticipantAudioEmotionAnalyzer, ParticipantSentimentAnalyzer, GlobalEkmanEmotionAnalyzer, GlobalNLTKTokenCountAnalyzer, ContributionAudioEmotionAnalyzer
# Initialize Analysis with desired Analyzers
analyzer = Analysis(
GlobalAudioEmotionAnalyzer(),
ParticipantAudioEmotionAnalyzer(),
ParticipantSentimentAnalyzer(),
GlobalEkmanEmotionAnalyzer(),
GlobalNLTKTokenCountAnalyzer(),
ContributionAudioEmotionAnalyzer()
)
# Run analyses
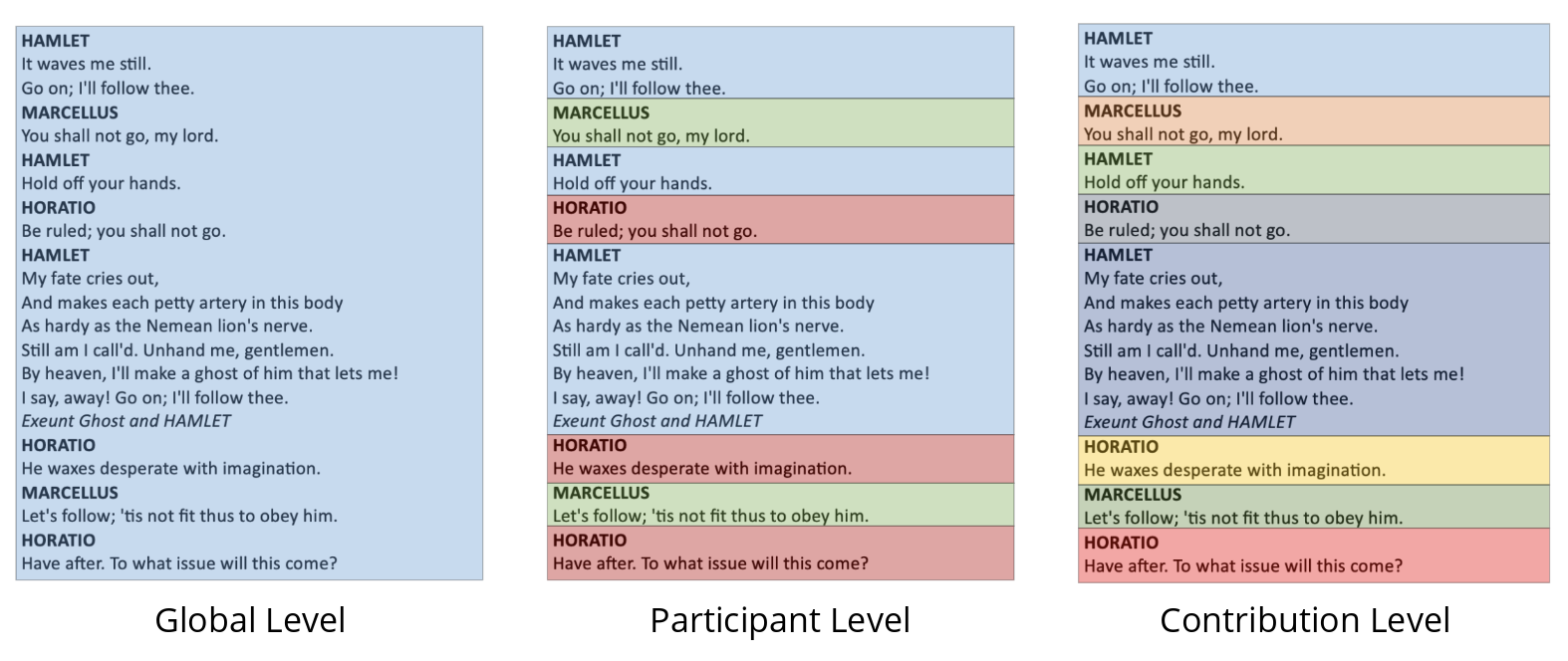
global_feat, participant_feat, contribution_feat = analyzer.analyze(data_json, audio, sr, video)When analyzing multimedia content with sociaML, understanding the context of the interaction is as crucial as the content itself. To provide a nuanced analysis, sociaML collects features at three different levels: Global, Participant, and Contribution. Below, we explain these concepts with an example from Shakespeare's Hamlet.
See the figure below for an illustration of these concepts:
Global features are derived by aggregating data across the entire video, without distinguishing between different participants. This level provides an overall summary of the video's characteristics, such as the general sentiment or mood throughout the play. For example, in a performance of Hamlet, global features would analyze the cumulative emotional tone of the entire play, providing insights into the overarching emotional landscape.
At the participant level, sociaML examines the data attributed to individual characters or speakers within the video. By focusing on each participant's contributions as a whole, we can compare and contrast different characters. For instance, in Hamlet, we could evaluate whether Hamlet exhibits a generally more negative sentiment compared to other characters like Horatio or Marcellus, or we might analyze the range of emotions that each character displays throughout the play.
The most granular level of analysis, contribution features, focuses on individual blocks of speech or action by a single participant. Each time a character speaks or performs an action uninterrupted, it's considered a single contribution. In our Hamlet example, this means analyzing specific speeches or soliloquies to determine the sentiment, emotions, and other features of that particular moment. For instance, we can analyze the emotional intensity of Hamlet's famous "To be, or not to be" soliloquy independently of the rest of the play.
If you have feature requests or want to co-develop this package please do not hesitate to reach out!
Developer
- David Zollikofer zdavid@ethz.ch
Previous Developers:
- Loïc Cabon lcabon@ethz.ch
Technical guidance by
This project stands on the shoulders of giants and merely provides a convenient wrapper for them. If you use sociaML in your research please cite the original models below:
Jochen Hartmann, "Emotion English DistilRoBERTa-base". https://huggingface.co/j-hartmann/emotion-english-distilroberta-base/, 2022.
Cheong, J. H., et al. "Py-Feat: Python facial expression analysis toolbox. arXiv [cs. CV]." 2021,
Plaquet, Alexis, and Hervé Bredin. "Powerset multi-class cross entropy loss for neural speaker diarization." arXiv preprint arXiv:2310.13025 (2023).
Bredin, H. (2023) pyannote.audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe. Proc. INTERSPEECH 2023, 1983-1987, doi: 10.21437/Interspeech.2023-105
Reimers, N. "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks." arXiv preprint arXiv:1908.10084 (2019).
Daniel Loureiro, Francesco Barbieri, Leonardo Neves, Luis Espinosa Anke, and Jose Camacho-collados. 2022. TimeLMs: Diachronic Language Models from Twitter. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 251–260, Dublin, Ireland. Association for Computational Linguistics.
Daniel Loureiro, Francesco Barbieri, Leonardo Neves, Luis Espinosa Anke, and Jose Camacho-collados. 2022. TimeLMs: Diachronic Language Models from Twitter. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 251–260, Dublin, Ireland. Association for Computational Linguistics.
Code is licensed under the permissive MIT license. Certain modules we depend on have different licenses though!