GPT
한글로 번역된 논문을 보고 이해된 내용입니다. (참고, GPT의 논문 제목은 Improving Language Understanding by Generative Pre-Training 입니다.)
번역한 이는 LM pre-training후에 fine-tuning이 어떻게 등장하였는지 소개한다는 점에서 GPT 논문의 기여를 찾고 있습니다.
- GPT는 transformer의 decoder를 사용합니다.
- BERT의 경우 transformer의 encoder를 사용합니다.
- GPT는 일반적인 LM을 사용합니다.
- BERT는 masked LM을 사용합니다.
- 일반적인 LM은 현재를 기준으로 다음을 예측하는 것을 의미합니다.
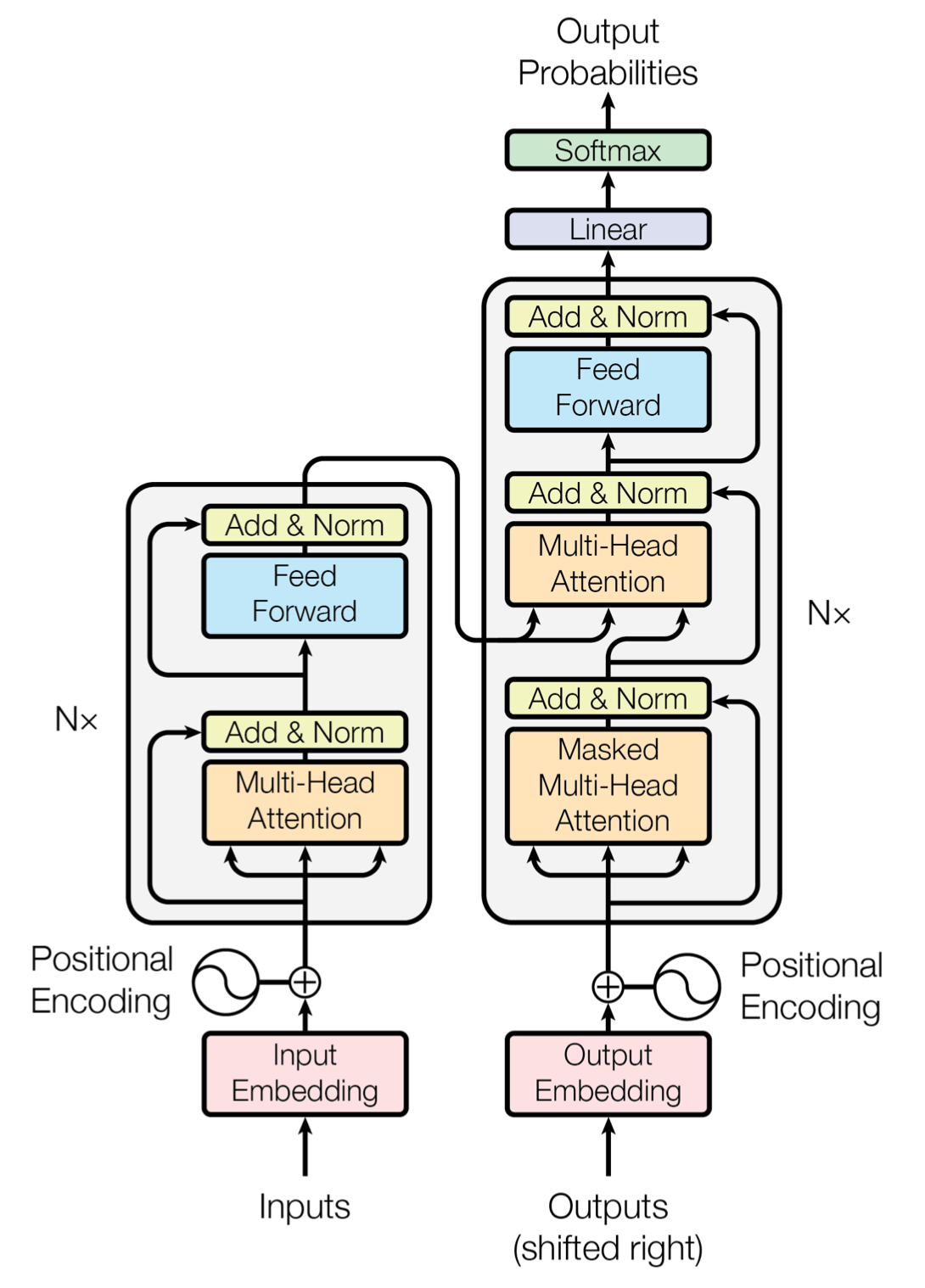
GPT의 목적은 Universal Representation을 학습하는 것입니다.
이 논문에서는 unsupervised pre-training + supervised fine-tuning을 결합하여 language understanding task에 대한 semi-supervised approach를 연구합니다.
이 과정은 두 단계로 이뤄집니다.
- 레이블되지 않은 데이터로 language model objective로 network 학습하고,
- target task를 위한 supervised object로 파라미터를 fine-tuning한다.
- 코퍼스
가 주어지면, 다음의 likelihood를 최대화하는 standard language modeling objective 사용
- k: context window 크기
-
: NN parameters
-
는 token context vector, n은 layer 수, We token embedding matrix, Wp는 positional embedding matrix일 때, 다음의 구조를 가진다.
LM objective에 대해 모델을 pre-training한 뒤, labeled dataset C를 가지는 target task에 대해 parameter 조정한다.
input tokens x1~ xn에 해당하는 label y 예측시, 마지막 transformer block의 activation hm_l을 input으로 하는 linear layer를 추가한다.
또한 추가로 auxiliary objective로 LM을 포함한다.
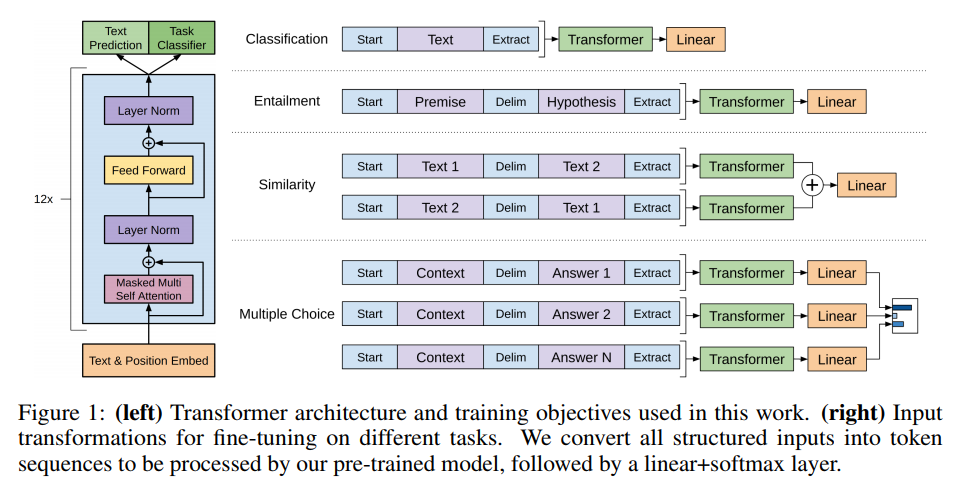
supervised fine-tuning을 어떻게 했는지에 대한 설명되어 있습니다.